Diffusion imaging is often included as a component of functional neuroimaging protocols these days. While fMRI examines functional changes on the timescale of seconds to minutes, diffusion imaging is able to detect changes over weeks to years. Furthermore, there may be complimentary information from the white matter connectivity obtainable from diffusion imaging – that is, from tractography - and the functional connectivity of gray matter regions that can be derived from resting state or task-based fMRI experiments.
I was recently made aware of some
artifacts on diffusion-weighted EPI scans acquired on a colleagues’ scanner.
When I was able to replicate the issue on my own scanner, and even make the
problem worse, it was time to do a serious investigation. The origin of the
problem was finally confirmed after exhaustive checks involving the assistance
of several engineers and scientists from Siemens. The conclusion isn't exactly
a major surprise: fat suppression for diffusion-weighted imaging of brain is
often insufficient. And it seems that although the need for good fat
suppression is well known amongst physics types, it’s not common knowledge in
the neuroscience community. What’s more, the definition of “sufficient” may
vary from experiment to experiment and it may well be that numerous centers are
unaware that they may have a problem.
Let’s start out by assessing a bad
example of the problem. The diffusion-weighted images you’re about to see were
acquired from a typical volunteer on a Siemens TIM/Trio using a 32-channel
receive-only head coil, with b=3000 s/mm2 (see Note 1), 2 mm
isotropic voxels, and GRAPPA with twofold (R=2) acceleration. These are three
successive axial slices:
 |
| (Click to enlarge.) |
The blue arrows mark hypointense
artifacts whereas the orange arrow picks out a hyperintense artifact. Even my
knowledge of neuroanatomy is sufficient to recognize that these crescents are
not brain structures. They are actually fat signals, shifted up in the image
plane from the scalp tissue at the back of the head. (If you look carefully you
may be able to trace the entire outline of the scalp, including fat from around
the eye sockets, all displaced anterior by a fixed amount.) I’ll discuss the
mechanism later on, but at this point I’ll note that the two principal concerns
are the b value (of 3000 s/mm2) and the use of a 32-channel array coil. GRAPPA isn’t
a prime suspect for once!
Now, part of the problem is that the
intensity of the artifacts – but not their location - changes as the direction
of the diffusion-weighting gradients changes. In the following video you see
the diffusion-weighted images as the diffusion gradient orientation is changed
through thirty-two directions (see Note 2):
The signal from white matter fibers
changes as the diffusion gradient direction changes. That’s what you want to
happen. But the displaced fat artifacts also change intensity with diffusion
gradient direction, meaning that the artifact is erroneously encoded as regions
of anisotropic diffusion. Thus, when one computes the final diffusion model,
the brain regions contaminated by fat artifacts end up looking like white
matter tracts. In the next figure the data shown above was fit to a simple
tensor model, from which a color-coded anisotropy map can be obtained:
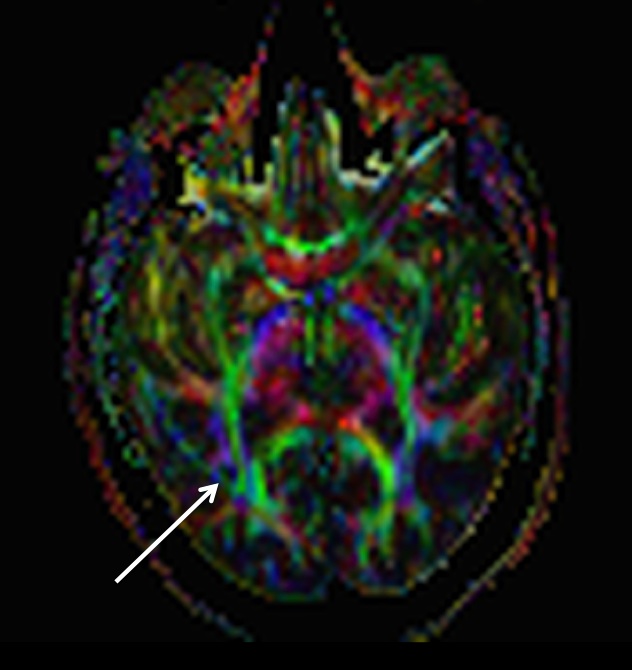
The white arrow picks out the false “tract”
corresponding to the artifact signal crescent we saw on the raw
diffusion-weighted images. I suppose it’s remotely possible that this is the
iTract, a new fasciculus that has evolved to connect the subject’s ear to his
smart phone, but my money is on the fat artifact explanation.
Clearly, in the above image there is
no easy way to distinguish the artifact from real white matter tracts by eye,
except by using your prior anatomical knowledge. And it's likely to confuse tractographic
methods, too, because it has very similar geometric properties to those that tractographic
methods attempt to trace. So let's take a look at the origin of the problem and
then we can get into what you want: solutions.
Fat head!
That's right, you heard me. You
probably already know about the subcutaneous fat (or lipid, if you prefer) that
surrounds the outside of your skull. While this relatively small amount of fat
helps keep your noggin warm and provides a modicum of cushioning for when you
bang your head on something, it's not ideal when it comes to brain imaging. The
problem is that fat protons - and there are lots of them because fat is
essentially long chains of carbons with 1-3 hydrogen atoms attached to each one - resonate at a different frequency than water
protons; a difference amounting to more than 400 Hz at 3 tesla. This so-called chemical shift difference causes a systematic spatial displacement of the fat
signal from the water signal. And because the phase
encoding dimension of a typical EPI has spatial information amounting to around
30 Hz per pixel, you can see immediately that a systematic 400 Hz offset
amounts to a shift of a dozen or more pixels in the phase encoding dimension. (See
Note 3.)
Scalp fat is thus a concern for all
EPI-based imaging. Fat suppression is therefore included as a standard step in
a typical EPI sequence for fMRI, for example.
In fMRI, insufficient fat suppression in EPI leads to larger than ideal ghosting, which can
cause regions of unnecessarily high signal variance for regions of the brain
overlapped by the fat ghosts, as well as the fat shift you saw above. But, as
will be discussed below, the requirements for fat suppression for diffusion
imaging can be even more stringent.
What can make the problem worse?
Why might EPI-based diffusion
imaging need enhanced fat suppression compared to EPI for fMRI? The simple
explanation is as follows: fat doesn't diffuse very quickly compared to water
in tissues. Thus, for any given diffusion weighting gradient value, the amount
of signal attenuation according to
S/S0 = e-bD, where S0 is the signal intensity with the diffusion gradient
turned off, is much lower for fat than for water because D, the diffusion
coefficient, is lower for fat than for water. When the b value starts to get
high the amount of residual water signal from brain tissue drops considerably,
making the residual fat signal comparable to the brain signals. If we now
couple a relatively intense fat signal with the spatial displacement arising
from the chemical shift… Presto! You have the problem we saw in the opening
figures.
Your immediate question is, of
course: “But if fat suppression is enabled as a standard step, why could I
possibly have a problem?” The prosaic answer is that the efficacy of the fat
suppression technique may be imperfect and may need to be adjusted depending on
the specific parameters you use for acquiring your diffusion data. We need to
evaluate a few aspects of the brain and fat signals in a little more detail.
As I mentioned above, the essential
issue here is one of relative signal magnitude, coupled with the displacement
of scalp fat signals into regions that should be occupied by brain only. If,
under diffusion weighting, the residual fat signals become significant relative
to the residual brain tissue water signals then we have a concern. And if, because
of the chemical shift, the scalp fat signals end up parked on regions that
should be occupied only by brain then we have a problem. So let’s next look at
a few of the situations where the residual fat signal may become problematic:
High b values - The higher the b value the greater the residual fat signal is likely to be relative to the brain water signal.A sensitive receiver array coil - Another good way to enhance the scalp fat signal is to use a very sensitive array coil, such as a 32-channel coil. The coil also boosts signal from the deeper brain signal to be sure, but the scalp fat is inconveniently located even closer to the coil elements and therefore gets an unwelcome supercharged boost. Note, however, that the fat artifact problem may arise with any RF coil.A long TE – Using an unnecessarily long TE will tend to preserve fat signal over water signal because fat has a long T2. Try to use the shortest possible TE for the b value that you want.In-plane parallel imaging – So, yeah, I lied ever so slightly earlier on. Although they aren’t the prime suspects because GRAPPA, SENSE and their ilk don’t create the fat artifact problem, they can exacerbate it because they tend to decrease the image SNR, especially the SNR of brain regions far from the periphery where the receive coil elements are located. (This is the so-called geometry, or g, factor.) There is also an overall root-R reduction of image SNR for R-fold acceleration.
Unfortunate head positioning – Some head sizes and shapes, and some head positions relative to the imaging gradients, may make the residual fat artifact more or less of a problem for you. The position of any fat artifacts will tend to vary slightly from subject to subject. Sometimes residual fat crescents may remain outside the brain, sometimes not. (See Note 4.)
Make it go away, please
How do you know if your fat suppression
scheme is sufficient, or that the imaging parameters render the experiment
vulnerable to fat artifacts parking themselves on the brain? Checking your
human brain data for fat artifacts may not suffice. As I've mentioned, it's
often quite difficult to detect by eye artifacts that are overlaying
complicated brain anatomy. The crescents from scalp fat look awfully like
genuine white matter tracts a lot of the time. There is also the issue of
biological variability to contend with. Just because the ten test subjects you
evaluate don’t exhibit a clear problem doesn’t imply that your experimental
subjects will always be problem-free. This is a situation where a phantom experiment
can really help.
Note how the olive oil signal has
been shifted into the region of image that should be occupied by water in the
sphere. (The olive oil is actually located a couple of centimeters beneath the
sphere.) And, of course, if the b value were increased beyond 1000 the residual
signal ratio of oil to water would be further enhanced.
On the product diffusion imaging
sequence (ep2d_diff) on my scanner there are three options to eliminate fat signals: fat
suppression (a.k.a. fatsat, based on a chemical shift-selective pre-pulse that targets
the fat protons), fat-selective inversion recovery (SPAIR - which uses an
inversion pulse targeted at just the fat resonances), and a composite
spatial-spectral pulse (usually called "water excite" because it is
designed to avoid the excitation of fat rather than eliminate the signal per
se). These three fat elimination schemes were compared on the same phantom setup.
Below are example diffusion-weighted
image data sets obtained from the oil-under-sphere phantom acquired with
(from left to right) fatsat, SPAIR and water excite:
 |
| Left to right: Fatsat, SPAIR and water excite fat suppression options on a product diffusion imaging sequence. |
None of the fat elimination options
on the product diffusion sequence was able to eliminate the fat signal. There
was a clear oil artifact – a bright crescent in this particular instance -
shifted into each image.
At which point I was out of options
with the standard (product) software, Syngo MR B17, on my Trio because there is
only the one diffusion-weighted EPI sequence. Fortunately, however, I have a
research diffusion imaging pulse sequence that has an option called "Extra Fat Suppr." (See
Note 5.) So I tried it. And finally the artifact could be eliminated! On the
left is the standard fat saturation while on the right is the Extra Fat Suppr.
option:
 |
| (Click to enlarge.) |
Note the complete elimination of fat
artifacts overlapping the water phantom only in the right-hand images. With
sufficient fat elimination, all that remains is a thin crescent of oil signal
located correctly underneath the water-filled sphere. The fat suppression
demonstrated on the right is what we require for diffusion imaging of human
brain. It implies that the b value could be increased, imaging parameters could
be altered, etc. and there would be no residual fat signal to be concerned
about.
Checking that you don't have a fat suppression problem
The need for excellent fat suppression for diffusion imaging is well known. I've included a couple of references in Note 6, papers that show examples of scalp fat artifact as strikingly as those you've just seen. But these relatively new methods may not be available on your scanner; they aren't on mine.
So, where does this leave you? Whichever
scanner and diffusion imaging pulse sequence you use, I would suggest checking
your fat suppression performance before applying it on a person. (Siemens
users, see Note 7.) It's easy enough to put some vegetable oil in a container
and include it with a water-filled phantom. You don't have to put the oil in a
bag like I did; I was trying to replicate a real scalp effect. But bags can
leak fairly easily and you don't want a mess to clean up! It should suffice to
include the oil in a small leak-proof plastic container. Then, once you have
your sample ready to test it's as easy as acquiring your diffusion imaging
protocol and assessing the raw, diffusion-weighted images. (See Note 8.) If
there's any doubt, disable the fat suppression scheme and do a comparison. The
difference with and without fat suppression should be striking.
_________________
Notes:
1. The so-called b value (or b
factor) is simply the reciprocal of the diffusion coefficient, hence the units
of s/mm2. D, the mean diffusivity (sometimes called the apparent
diffusion coefficient, ADC) is in units of mm2/s. The b value takes
into account all of the dephasing caused by applied magnetic field gradients
(it doesn't include dephasing caused by magnetic susceptibility gradients
because these are unknown) in a simple term that relates signal loss according
to:
S/S0 = e-bD
where S0 is the signal in the
absence of applied diffusion gradients. The imaging gradients themselves should
be included in the calculation of b, although for conceptual simplicity we can
think of b=0 for an image with no diffusion weighting gradients enabled.
2. It doesn’t actually matter
what these directions were or why there were 32 of them in order to understand
the artifact and why it’s a problem. But in case you know about such things, it
was to fit to a HARDI model and this was half of the total data acquired. Diffusion
scans differ in how the gradients are applied because different models of
diffusion may be used to reconstruct the data. A simple tensor process may be
used, for instance. Several models use a fixed magnitude of the b value (which
is, strictly speaking, a 3x3 matrix for 3D gradient encoding and not a single
number) and simply rotate its direction. The trigonometry is done behind the
scenes. This is akin to sampling different points on a sphere of constant b
radius.
3.
There is also a smaller shift of about a quarter of a pixel in the readout
dimension, which we can safely ignore. The effect is far smaller in the readout
dimension than in the phase encoding dimension of EPI because the readout
gradient bandwidth is typically between 1500-3000 Hz per pixel. It’s also
useful to recognize that the chemical shift difference between water and fat
scales in proportion to the magnetic field strength, making the effect at 3 T twice as bad as at 1.5 T.
4. It would be terrific if
there were a reliable way to arrange the phase encoding parameters such that
the fat artifacts always fell in non-critical parts of the image. This is
easier said than done, however. One tactic might be to adjust the head position
relative to the phase encode gradient center such that the crescents fall
mostly outside of the brain. Another tactic is to increase the image
field-of-view (FOV), but that is inefficient use of spatial encoding. You could
try swapping the readout and phase encoding axes, thereby putting the fat
artifacts in the orthogonal dimension; left-right in the case of the axial
slices shown so far. But that causes the phase encode distortion to also shift
to the L-R direction, and people seem to have an inherent dislike of kidney
bean-shaped brains (even if the actual distortion level is similar on a
quantitative basis). Finally, you could try reversing the phase encoding axis;
here it would be P-A from A-P. Altering the phase encoding axis necessarily
alters the distortion: compressions in A-P become stretches in P-A, and vice versa. Furthermore, you may have to
choose between signal from the back of the head being displaced up into the
brain for one phase encoding direction, versus fat signal from the forehead
being displaced down into the brain if the phase encode direction is reversed!
Pick your poison. Similarly, if the phase encoding dimension is left-right (for
axial slices) then the scalp fat from one side or other will be displaced into
the brain; you only get to choose which
side gets contaminated in selecting the phase encode direction. None of these
tricks is ideal, and none would be easy to implement across an array of
disparate heads.
5. I don't know what the extra
fat suppression option is doing except that it increases the minimum TE by
about a millisecond, so it may be adding an extra fat suppression pulse. I
honestly can't tell you right now, but I'll add a footnote to this post if I
ever find out.
6.
Some references for more
information on improved fat elimination schemes, including examples of the problem:
Robust fat suppression at 3T in
high-resolution diffusion-weighted single-shot echo-planar imaging of human
brain.
JE Sarlls, C Pierpaoli, SL Talagala, WM Luh. Magn. Reson. Med. 66(6):1658-65 (2011).
PMID: 21604298
DOI: 10.1002/mrm.22940
JE Sarlls, C Pierpaoli, SL Talagala, WM Luh. Magn. Reson. Med. 66(6):1658-65 (2011).
PMID: 21604298
DOI: 10.1002/mrm.22940
Efficient fat suppression by
slice-selection gradient reversal in twice-refocused diffusion encoding.
Z Nagy, N Weiskopf. Magn. Reson. Med. 60(5):1256-60 (2008).
Z Nagy, N Weiskopf. Magn. Reson. Med. 60(5):1256-60 (2008).
DOI: 10.1002/mrm.21746
7.
If you own a Siemens scanner running Syngo MR B15 or B17 (which includes
Trio and Verio scanners), you have the product diffusion imaging sequence
(ep2d_diff) as your only option, and you find that your fat suppression is
insufficient when you test then you may want to talk to your local applications
support people. To my way of thinking, insufficient fat suppression is a pulse
sequence bug that should be patched. However, if you are fortunate to have a
research agreement with Siemens then you should be able to get a
work-in-progress (WIP) sequence to use instead of ep2d_diff. I tested the WIP
sequence numbered 511E, but I note that 511C also has the Extra Fat Suppr.
option in it. Finally, I found a document online that claims Syngo MR D11, the software
that comes on the Magnetom Skyra 3 T scanner, has "improved fat saturation
schemes" as part of the product diffusion sequence. I haven't seen it or
tested it for myself, but I would hope that the performance of the WIP sequence
I have tested is matched in the latest product.
Update (4th March, 2013): There is an "extra fatsat" option on the product diffusion imaging sequence (ep2d_diff) available on the Skyra running Syngo MR D11. I haven't tested the standard or the extra options but I would bet considerable money that the "extra" option is required in order to fully eliminate scalp fat signal with b > 1000 s/mm^2.
Update (4th March, 2013): There is an "extra fatsat" option on the product diffusion imaging sequence (ep2d_diff) available on the Skyra running Syngo MR D11. I haven't tested the standard or the extra options but I would bet considerable money that the "extra" option is required in order to fully eliminate scalp fat signal with b > 1000 s/mm^2.
8. You should test the
diffusion protocol as similarly as possible to the conditions to be used for
brain imaging. However, if you use b values significantly above 1000 you won't
see very much residual water signal in an isotropic water phantom. That may not
be a big deal because it would still be possible to see chemical shift
artifacts from an oil sample once the water signal has been eliminated. Indeed,
there's no strict need to have a water phantom in the coil with the oil at all!
But I prefer to have a water signal to shim on, and to have a water signal
background against which to contrast residual fat signals. It's all a matter of
preference, and my preference is to maintain all other parameters as used in
the brain experiment, but to reduce the b value to 1000 for testing purposes.
If I was paranoid I might then repeat the tests with the higher b value of an
actual experiment, but once I'm satisfied the fat suppression is working at
b=1000 then I am confident it will work well at other values.
Thanks Ben! Please do post if you come up with any other work arounds!
ReplyDeleteThank you for bringing the attention to this artifact. I have noticed that my data occasionally suffer from fat artifacts (B strength 850s/mm2). I am not an MRI expert and don't know how to fix the problem without affecting the quality of the data. Beside, the B value is standard in our studies and can't really change it to a lower value now. The scanner is a Philips Achieva 3T. What would you advise in this case? Are there solutions to fix the problem and keep going on the current studies, or do I have to carefully wait when studies are finished (i.e. years) to take care of the fat.
ReplyDeleteP.s. In one of the subjects the fat was so visible (ring type) that I thought the guy had an additional commisure anterior to the corpus caollosum. :)
Dorian
Hi Dorian, don't wait!!! Get your physicist to contact your local applications support person. There may be a way to improve the fat suppression without any drastic changes to your protocol. (Indeed, first order of business is to ensure that fat suppression is actually enabled, if it's *that* bad.)
ReplyDeleteSure, someone could accuse you of changing your experiment partway through, but do you really want 100% of your subjects with crappy, potentially useless data? Of course not. Besides, since the amount of fat on a person changes across a group, the effect of the artifact is already variable. Changing the fat suppression alone, all diffusion and timing parameters remaining constant, should simply clean up what might otherwise be a systematic confound.
Got a Skyra running Syngo MR D11? Then please see my update to note #7.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteNice post, but remains me a doubt at issue "What can make the problem worse? / a long TE" :
ReplyDeleteIs water t2 shorter than fat, indeed? Ithought that is inverse, fat T2 is shorter than water...Is that item correct, if yes, someone could explain me why. thanks!
Hi Bruno, yes, the fat T2 is generally shorter than brain tissue T2 but not by much, and it is sufficiently long, with comparatively short apparent diffusion coefficient, that the relative strength of the fat signal will be high compared to the tissue signal once the diffusion weighting is applied. For a given b value, then, one wants the shortest TE possible to minimize T2 weighting of the desired water signal as well as to minimize any artifacts. Really, though, you're right in that it doesn't make a big difference, i.e. that a short TE will make the problem better. Fat artifacts are bad no matter what, they just become more prominent in the DW images when the brain signals are weaker.
DeleteNice post, but remains me a doubt at issue "What can make the problem worse? / a long TE" :
ReplyDeleteIs fat t2 shorter than water, indeed?
Thank you for a great post! I would like to ask an elementary question. According to the post, signal intensity of chemical shift artifacts, i.e., the sum of water and fat signals, can be high intensity or low intensity compared to the water signal. In the case of high intensity, it is quite intuitive to me. That is, if the water signal and the fat signal are 100 and 10, respectively, then the signal of chemical shift artifact is 110, which is a high signal relative to the water. On the other hand, what I do not understand is the case of a low signal case. For example, if the signal of the water is 100 and the signal of the artifact (water and fat) is 90, then the signal of the fat must be -10, i.e., a negative signal. How should we interpret this negative signal??
ReplyDeleteSeina from Japan
Really sorry for the lengthy delay, I haven't been near by blog for some time!
DeleteI think you have misunderstood chemical shift hence chem shift artifacts. The CSA isn't the sum of the water and fat signals. The fat signals resonate at a different frequency (circa 700 Hz away) from water. Since we use frequency encoding to establish the spatial parameters in the image, this ~700 Hz offset means an image of fat will appear a few pixels displaced from an image of water. This is true whether the fat or water signals are intense or weak. But if the fat signals happen to be intense then the displaced image can be a significant distraction and, for diffusion imaging specifically, where the fat image overlaps the water image can produce false 'tracts' in the data that have nothing to do with water translational diffusion.